
摘要 为提高孤立词语音识别正确率,提出将卷积神经网络应用于孤立词语音识别的方法。搭建具有4个卷积层、4个汇聚层和2个全连接层的一维卷积神经网络模型。将语音重采样为相同长度后输入到网络模型中进行识别,在TensorFlow语音识别挑战赛数据集上,实验结果表明,模型的识别正确率为92%。为方便语音识别,基于PyQt5搭建可视化孤立词识别系统,系统简洁易用,识别速度快、准确率高。
关键词: 孤立词语音识别; 卷积神经网络; 重采样; 可视化识别系统
语音识别技术,也被称为自动语音识别或语音转文本识别,其目标是以电脑自动将人类的语音内容转换为相应的文字。孤立词识别是指语音中只包含一个词语的识别。传统的孤立词识别方法主要有两种: 一是动态时间规整(Dynamic Time Warping, DTW)方法, 二是隐马尔可夫模型(Hidden Markov Model, HMM)的方法。前者由于没有一个有效地用统计方法进行训练的框架, 且不方便将低层和顶层的各种知识用到语音识别算法中, 在解决大词汇量、非特定人语音识别等问题时效果较差;而HMM算法比较复杂,需要在训练阶段提供大量的语音数据, 通过反复计算才能得到参数模型。神经网络是机器学习与人工智能领域的一种模型,近几年来,深度神经网络(Deep Neural Networks, DNN)在语音识别领域的应用大幅度地提高了已有语音识别系统的准确率,使得语音识别技术变得更加可用,使用机器学习方法提高语音识别系统性能是一个重要的研究课题, 本文主要研究卷积神经网络(Convolutional Neural Network, CNN)在孤立词语音识别问题中的应用。
1 基于CNN的孤立词识别模型
1.1 卷积神经网络简介
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。CNN将模式识别的特征提取和模型分类两个问题统一到一个网络中来,本质上是一种由一组或多组卷积层和池化层交替连接构成的基于有监督学习的数学模型。
CNN的基本结构由输入层(input layer)、卷积层(convolutional layer)、汇聚层(pooling layer)、全连接层(full connection layer)以及输出层(output layer)构成。卷积层和汇聚层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。这些层结构依次堆叠形成一个卷积神经网络。
通常情况下,语音识别都是基于时频分析后的语音谱完成的,而其中语音时频谱是具有结构特点的。要想提高语音识别率,就是需要克服语音信号所面临各种各样的多样性,包括说话人的多样性(说话人自身、以及说话人间),环境的多样性等。一个卷积神经网络提供在时间和空间上的平移不变性卷积,将卷积神经网络的思想应用到语音识别的声学建模中,则可以利用卷积的不变性来克服语音信号本身的多样性。从这个角度来看,则可以认为是将整个语音信号分析得到的时频谱当作一张图像一样来处理,采用图像中广泛应用的深层卷积网络对其进行识别。同时,CNN也比较容易实现大规模并行化运算,且CNN的加速运算相对比较成熟,一些通用框架如Tensorflow等都提供CNN的并行化加速,为CNN在语音识别中的尝试提供了可能。
1.2 基于CNN的孤立词识别模型
词语范围固定的孤立词识别问题,本质上属于一个多分类问题,输入为语音信号,输出为语音信号对应的词语文字。针对这一问题,搭建了具有4个卷积层、4个汇聚层和2个全连接层的一维卷积神经网络,网络结构如图 1所示。
输入为语音的时域信号,首先经过四层卷积层和池化层的深层特征提取和降维,然后进入全连接层把提取到的局部特征进行全局上的整合与变换,最后经过Softmax得到语音属于不同分类的概率。网络搭建的核心代码如下:
1 | inputs = Input(shape=(8000,1)) |
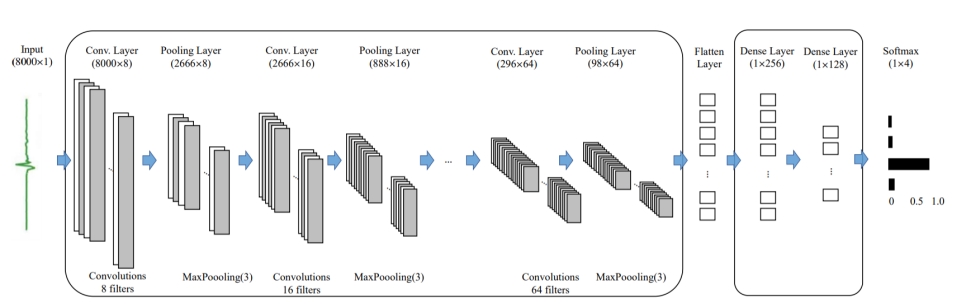
1.3 模型应用及性能评估
实验所用的数据集来自TensorFlow语音识别挑战赛。
上述模型应用于语音处理的流程如图 2所示:
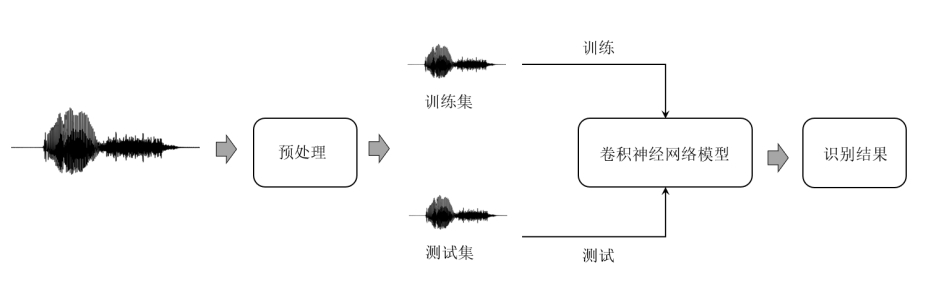
首先,对数据进行预处理。实验选择”yes”, “no”, “up”, “down”四个孤立词识别。首先删除音频长度< 1秒的语音;然后对剩余语音进行重采样处理,由于人类的语音信号的频率大部分在 10000Hz 以下,电话信号的采样率为 8000Hz,因此实验也将原语音信号重采样到8000Hz(原采样率为16000Hz);最后对输出标签编码,先将输出标签转换为整体编码,再进行One-hot编码处理,同时,输入信号转化为3维。
然后,划分训练集和数据集,实验以8:2的比例进行划分。
再将训练集输入到搭建好的模型中进行训练。训练过程中,损失变化如图 3所示:
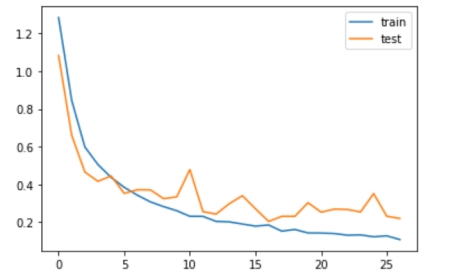
最后,利用测试集检验模型性能。结果显示,测试集语音总条为1694,其中预测正确条数有1573,预测错误条数有121,即在测试集上的正确率92.86%。
2 基于PyQt5的孤立词识别系统
为方便识别过程,搭建了基于PyQt5的简易孤立词识别系统,系统主界面如下图所示:
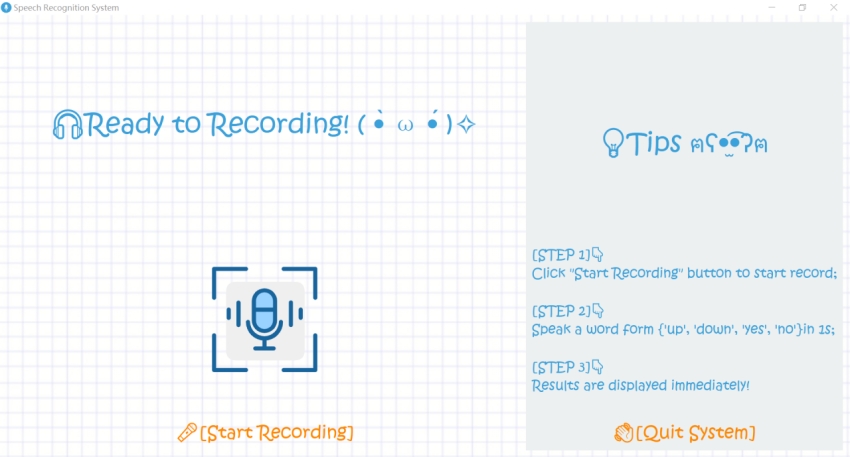
界面左边为语音识别区域,右边为系统使用说明区域。
点击[Start Recording]按钮即开始录音,录音时间为1s, 录音界面如下图:
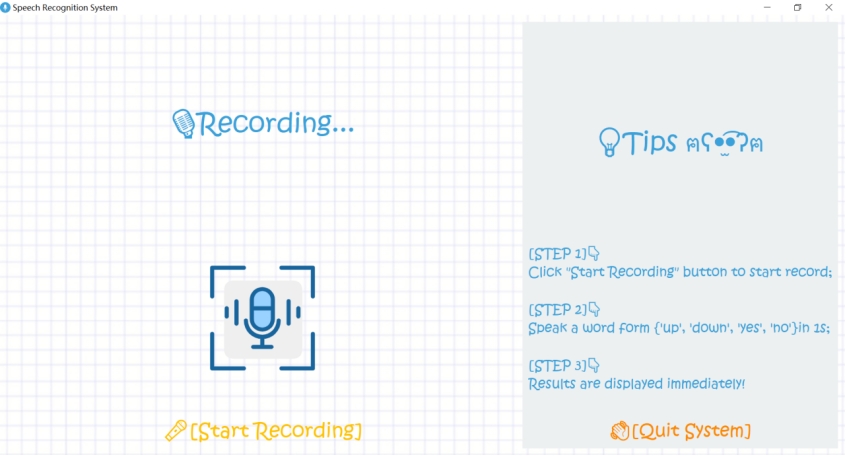
录音完成,系统调用训练好的CNN孤立词识别模型对语音进行识别,识别完成,立即展示识别结果,如下图所示:

3 总结
本文提出了基于卷积神经网络的孤立词语音识别方法。搭建了具有4个卷积层、4个汇聚层和2个全连接层的一维卷积神经网络模型。利用TensorFlow语音识别挑战赛数据集对模型进行训练、测试,实验结果表明,模型在测试集上的识别正确率为92%。同时,为模型使用,基于PyQt5搭建了可视化孤立词识别系统,系统简洁易用,识别速度快、准确率高。
由于时间资源有限,模型仅能用于识别”yes”, “no”, “up”, “down”四个孤立词,如需识别其他词,还有重新训练;另外,卷积神经网络的许多参数还有待改进,以减少训练时间。
参考文献
[1]侯一民,李永平.基于卷积神经网络的孤立词语音识别[J].计算机工程与设计,2019,40(06):1751-1756.
[2]Semin Ryu,Seung-Chan Kim. Knocking and Listening: Learning Mechanical Impulse Response for Understanding Surface Characteristics[J]. Sensors,2020,20(2).
[3]朱锡祥,刘凤山,张超,吕钊,吴小培.基于一维卷积神经网络的车载语音识别研究[J].微电子学与计算机,2017,34(11):21-25.